robots协议或者说robots文件对搜索引擎优化中非常重要,但设置出错可能会导致收录下降或不能正常收录。今天,小小课堂SEO自学网带来的是《【robots文件协议】解除Robots封禁全过程》。希望本次的百度SEO优化培训对大家有所帮助。
一、robots被封禁的问题来源
小小课堂SEO自学网为WordPress博客,前几天弄了个“SEO问答”的栏目,是由一个新的CMS系统创建而成的,而这个系统是动态URL,未做伪静态处理。
SEO问答首页的URL:https://www.***.org/ask/
SEO问答栏目的URL:https://www.***.org/ask/?expert/default.html
SEO问答文章列表的URL:https://www.***.org/ask/?c-1.html
SEO问答文章的URL:https://www.***.org/ask/?q-176.html
从上可以看出除了SEO问答首页,其余的都是带问号的,然而,WordPress根目录的robots.txt中包含了以下一条:
Disallow: /*?*
因为这一条的意思是禁止访问网站中所有包含问号(?) 的网址,所以上面的那些带问号的URL就被禁止搜索引擎抓取了。
二、解除Robots封禁全过程
小小课堂SEO自学网解除robots文件协议的全过程如下:
① 去掉robots禁止抓取的规则
也就是去掉Disallow: /*?* 。
② 抓取失败
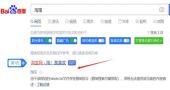
进入百度站长后台后,点击“数据监控”>“抓取诊断”>输入网址后面的部分,最后点击抓取。
③ 点击“抓取失败”
通过下图可以看出“抓取异常信息:Robots封禁”,点击“网站IP:106.***.***.217”后面的“报错”。略等一会即可。
④ Robots检测并更新
点击检测并更新robots。
以上就是小小课堂SEO自学网带来的是《【robots文件协议】解除Robots封禁全过程》。感谢您的观看。网络营销培训认准小小课堂!SEO培训认准小小课堂!更多seo教程搜索小小课堂。原创文章欢迎转载并保留版权:https://www.xxkt.org/
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!