robots.txt直接放在网站根目录下,是蜘蛛访问网站时,第一个抓取的文件。robots.txt是告诉蜘蛛网站的哪些文件允许抓取,哪些文件不允许抓取,甚至可以指定特定的蜘蛛能不能抓取特定的文件。没有抓取就没有收录,没有收录就没有排名。所以作为第一蜘蛛访问的文件,写好robots.txt是很重要的,写好robots.txt后,一定要再检查一两遍,以防出错。这里总结下robots.txt写法,让你看完秒懂robots.txt写法和注意事项 。
一.robots.txt具体作用
1.对搜索引擎做出规定,抓取或者不抓取。
2.由于有些信息规定了不让抓取,所以可以保护到一些必要的信息,比如:网站后台,用户信息。
3.节省搜索引擎抓取资源。
二.robots.txt规则
1.User-agent,用于告诉识别蜘蛛类型。比如,User-agent: Baiduspider 就是指百度蜘蛛。
各类蜘蛛列举如下:
百度蜘蛛:Baiduspider
谷歌机器人:GoogleBot
360蜘蛛:360Spider
搜狗蜘蛛:Sogou News Spider
雅虎蜘蛛:“Yahoo! Slurp China” 或者 Yahoo!
有道蜘蛛:Youdaobot 或者 Yodaobot
Soso蜘蛛:Sosospider
2.Allow,允许蜘蛛抓取指定目录或文件,默认是允许抓取所有。
3.Disallow,不允许蜘蛛抓取指定目录或文件。
4.通配符,“*”,匹配0或多个任意字符。
5.终止符,“$”,可以匹配以指定字符结尾的字符。
举个例子:下面是一个wordpress程序的robots.txt
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
Disallow: /*.js$
Disallow: /*?*
Sitemap: http://www.leheseo.com/sitemap.xml
解释:
User-agent: *:对所有搜索引擎都使用下面的规则。
Disallow: /wp-admin/:不让蜘蛛抓取根目录下的wp-admin文件夹。
Disallow: /*.js$:不让蜘蛛抓取根目录下所有的js文件。
Disallow: /*?*:不抓取所有的动态链接。
Sitemap: http://www.leheseo.com/sitemap.xml:给蜘蛛提供网站地图,方便蜘蛛抓取网站内容。
三.robots.txt注意事项
1.如果你希望搜索引擎收录网站上所有的内容,那么就不要建立robots.txt文件。
2.如果同时存在动态和静态链接,那么建议屏蔽动态链接。
3.robots.txt只能是屏蔽站内文件的,对站外文件没有屏蔽功能。
4.User-agent,Allow,Disallow,Sitemap的首字母都是大写的。
5.User-agent,Allow,Disallow,Sitemap的冒号后面都是有空格的,没有写空格直接写接下来的内容会出错。
6.网站通常会屏蔽搜索结果页面。因为搜索结果页和正常展示的内容页相比,标题和内容上相同的,而这两个页面链接是不同的。那搜索引擎该将这篇文章归属于哪个内链呢?这样就会造成内链之间相互竞争,造成内部资源损耗。
比如上面举的例子,那个wordpress程序,在没有设置伪静态,还是动态链接的时候,搜索结果页面链接都包含有/?s=,而 标题和内容 与 正常展示的动态链接内容页重复,可以通过Disallow: /?=*来屏蔽搜索结果页面。
而现在那个wordpress程序已经设置了伪静态,也设置了Disallow: /*?*,Disallow: /*?*本身就包含了Disallow: /?=*,所以Disallow: /?=*这句写不写都没有关系
7.建议屏蔽js文件。Disallow: /*.js$,以 .js 结尾的路径统统被屏蔽,这样就屏蔽了js文件。
8.路径是区分大小写的。Disallow: /ab/ 和 Disallow: /Ab/ 是不一样的。
9.robots.txt会暴露网站相关目录,写robots.txt时要考虑到这一点。
10.有些seo会将文件直接备份在服务器中,文件是 .zip 格式,然后在robots.txt中屏蔽。个人不建议这样,这就是明显告诉人家你的备份文件位置。建议文件和数据都备份到本地。
11.一些特殊规则对比:
①Disallow: /和Disallow: / ab (/后面有个空格,再有ab)是一样的,/后面多了个空格,蜘蛛之认空格前面那一段,就是Disallow: /,所以两个都是屏蔽整站的。
②Disallow: /ab和Disallow: /ab*是一样的。比如两个都能屏蔽http://域名/ab,http://域名/abc,http://域名/abcd。
③Disallow: /ab/和Disallow: /ab是不一样的。很明显,Disallow: /ab范围更广,包含了Disallow: /ab/。因为Disallow: /ab/只能屏蔽http://域名/ab/,http://域名/ab/....这样的路径,也就是只能屏蔽ab目录和ab目录下的文件不被蜘蛛抓取。
四.验证robots.txt文件的正确性和是否生效
当我们写好了robots.txt文件后,怎么确定文件的正确性呢?上传到服务器根目录后,怎么判断robots.txt文件是否生效了呢?这时我们可以借助百度资源平台Robots。比如输入乐呵SEO测试服网址,得到如下结果。
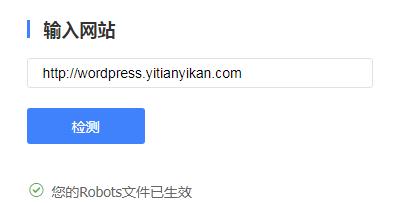
验证robots.txt文件是否生效
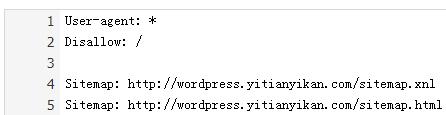
检测到robots.txt文件的内容
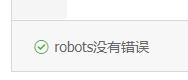
验证robots.txt文件的正确性
结果证明,http://wordpress.leheseo.com/robots.txt这个文件没有语法错误,并且已经生效了。
若是想测试某一个目录或者文件是否被屏蔽了,百度也是提供了工具的。如下图,由于 http://wordpress.leheseo.com 是测试服,我屏蔽了所有文件。所以无论我输入根目录下的任何目录或者任何文件,都是检测不到的,也就是说蜘蛛是抓取不到的。
输入了后台目录wp-admin:
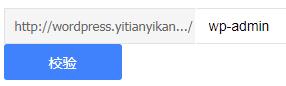
后台目录检测结果:
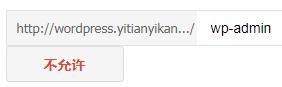
经过测试,其他文件和目录页也检测不到,所以这个功能还是很好用的。
更多robots.txt内容,可以参考百度提供的文档哦。https://ziyuan.baidu.com/college/courseinfo?id=267&page=12
robots.txt写法和注意事项就总结到这里了,内容相对细致,结合了例子讲解会很容易看懂,希望对您有所帮助咯。
原创文章,作者:乐呵seo,如若转载,请注明出处:http://www.leheseo.com/seojiaocheng/282.html
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!