




芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西12月6日圣何塞报道,北京时间12月7日凌晨,芯片巨头AMD的年终AI盛会Advancing AI活动正式举行。在AI芯片赛道愈战愈勇的AMD今天会放出怎样的大招,着实令人期待,为此芯东西早早来到会场,翘首等待被粉丝们亲切称作“苏妈”的AMD CEO苏姿丰发表主题演讲。

今天加州的阳光依然灿烂,当地时间10点一到,大会正式开场,苏妈健步如飞地走上台,笑容满面地分享对人工智能(AI)计算的观察思考,将AI评价为“过去50年来最具变革性的技术”,称生成式AI是“最刚需的数据中心工作负载”。

会上,AMD宣布推出旗舰数据中心AI芯片AMD Instinct MI300X GPU ,并在多项硬件规格及大模型训推测试上与英伟达正面交锋。
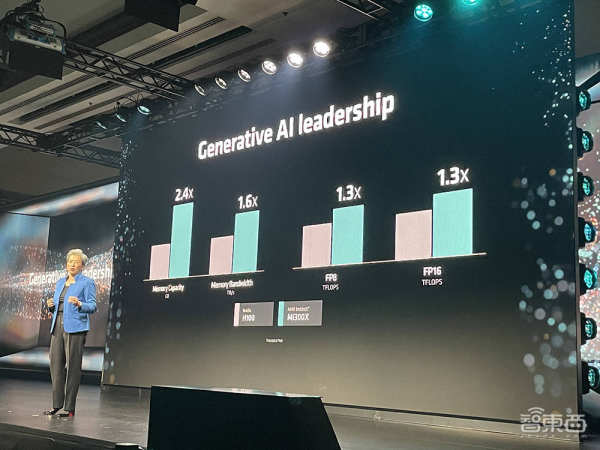
AI峰值性能、内存密度、内存带宽,这些关键硬件规格通通秒掉英伟达旗舰AI芯片H100 GPU!也就是说,相比英伟达H100,MI300X能跑更大参数规模的大模型。
这是一场AMD全面展示其AI战略雄心的盛会,除了MI300X外,AMD还宣布推出结合最新AMD CDNA 3架构和“Zen 4”CPU的MI300A加速处理单元(APU) ,以及让笔记本电脑能够更轻松添加AI功能的Ryzen 8040系列移动处理器 。
此外,AMD剧透了Ryzen AI路线图,代号为“Strix Point ”的下一代Ryzen AI CPU将在2024年出货,采用XDNA 2架构。XDNA 2架构的生成式AI NPU性能将提高到上一代的3倍以上。

软件方面,AMD发布了最新版本的ROCm 6 开放软件堆栈,该堆栈针对生成式AI(尤其是大语言模型)进行了优化。相较MI250搭ROCm 5,MI300X与ROCm 6双强组合在Llama 2上生成文本的总体延迟性能提高了约8倍 。
与Ryzen 8040系列处理器同时登场的Ryzen AI 1.0软件栈 ,使开发者能够轻松部署使用预训练模型为Windows应用程序添加AI功能。

一、MI300X:内存容量带宽超H100,更快畅跑千亿参数大模型
苏姿丰说,一年前,AMD预估全球数据中心AI芯片/GPU的TAM将从2023年的300亿美元增长到2027年的1500亿美元,未来4年CAGR增速将超过50%。但显然需求增长得更快,现在AMD将其预估修正为数据中心加速器未来四年每年增长70%以上,到2027年将超过4000亿美元。

她分享道,AMD的AI战略围绕三大重点:1)提供高性能、高能效的GPU、CPU和用于AI训练及推理的自适应计算解决方案的广泛组合;2)扩展开放的、经验证的、对开发人员友好的软件平台;3)扩大深度协同创新的AI生态系统。

为了解决GPU硬件可用性问题,AMD推出Instinct MI300X加速器。
苏姿丰称MI300X加速器是AMD迄今制造过的最先进的产品、“业界最先进的AI加速器”,拥有1530亿颗晶体管、192GB HBM3内存容量、5.3TB/s峰值内存带宽、896GB/s Infinity Fabric互连带宽,能支撑大模型训练和推理。
大模型拼算力,关键就是看内存容量和带宽,所以相比英伟达H100的96GB内存、3.2TB/s带宽,MI300X在硬件配置上很有吸引力。
MI300X把4个SoC Die都用来放GPU,8个HBM3升级到24GB,形成了一个由8颗CDNA 3架构Accelerator Complex Die(XCD)、4个I/O Die(IOD)、8个HBM内存堆栈组成的共有12颗5nm Chiplet的集成系统。Chiplet的好处是提高良率和降低成本,因此MI300X可能会在定价上比H100/H200更具性价比。

通过这种“拼芯片乐高”的方式,MI300X实现了计算核数、带宽及内容容量的显著增加。其采用的CDNA 3架构对性能和能效进行了优化,结合了一个新的计算引擎,支持稀疏性和TF32、FP8等新数据格式,为关键数据类型(如FP16/BF16)提供的性能达到上一代的3.4倍。

相比上一代MI250X,MI300X增加了近40%的计算单元、1.5倍的内存容量、1.7倍的峰值理论内存带宽,并支持FP8和稀疏性等新数值格式。
微软CTO凯文·斯科特来到现场介绍微软与AMD的合作进展。MI300X芯片将为针对AI工作负载进行优化的全新Azure ND MI300x v5虚拟机系列提供动力。

多个GPU互连性能需要线性提高,因此可扩展性至关重要。苏姿丰说,MI300X平台是世界上最强大的生成式AI系统。

AMD Instinct MI300X平台是一个内置8个MI300X的OCP标准整机形态,BF16/FP16峰值算力可达到10.4PFLOPS,总共可提供1.5TB的HBM3内存容量,这两个规格都高于英伟达H100 HGX。

在跑不同Kernel的Flash Attention 2、Llama 2 70B大模型时,MI300X均表示出优于H100的性能。
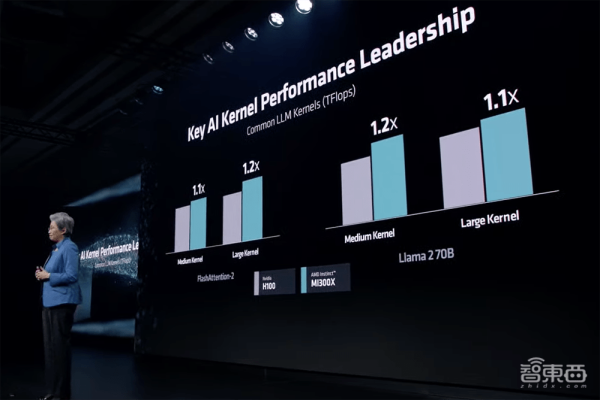
8卡AMD Instinct MI300X平台在BLOOM 176B大语言模型上跑推理的吞吐量达到英伟达H100 HGX的1.6倍。
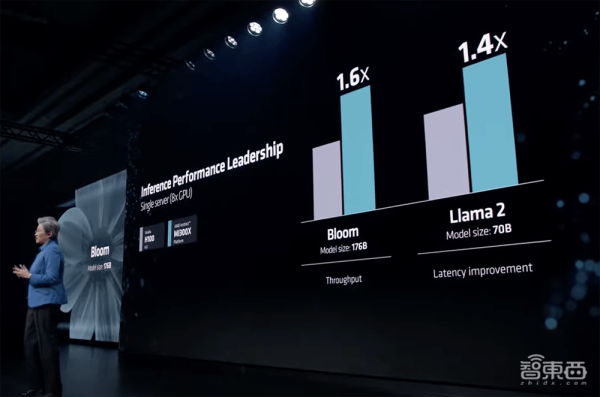
在训练拥有300亿参数的MPT模型时,MI300X平台与H100 HGX的吞吐量持平。

同等性能的单个系统跑大语言模型时,无论是训练还是推理,MI300X平台的性能都超过H100 HGX。

Oracle云基础设施计划将基于MI300X的裸机实例添加到该公司为AI的高性能加速计算实例中,基于MI300X的实例计划通过超高速RDMA网络支持OCI超级集群。其即将到来的生成式AI服务中也将包含MI300X。
惠普、戴尔、联想、超微、技嘉、鸿佰、英业达、云达、纬创、纬颖等都是MI300X芯片的OEM和解决方案合作伙伴。
二、MI300A:APU四大优势加持,高性能计算能效比超GH200
AMD Instinct MI300A APU是世界上第一个用于HPC和AI的数据中心APU,采用3D封装和第4代AMD Infinity架构。

该加速器结合了6个CDNA 3架构Accelerator Complex Die(XCD)、3个CPU Complex Die(CCD,共24个x86“Zen 4”核心)、4个I/O Die(IOD)、8个HBM内存堆栈、128GB新一代HBM3内存。

MI300A同样遵循Chiplet设计思路,并实现了CPU与GPU共享统一内存。
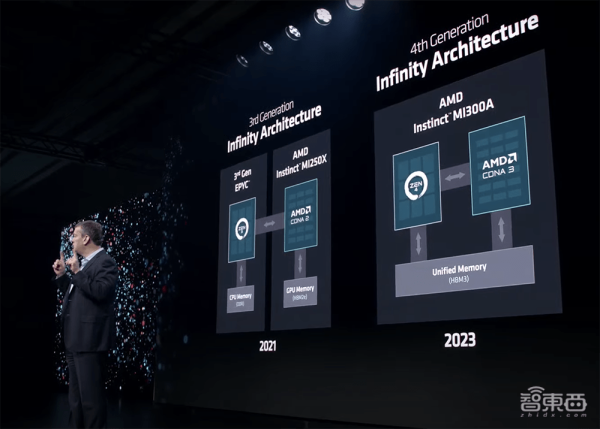
与MI250X相比,MI300A在FP32 HPC和AI工作负载上提供了约1.9倍的每瓦性能;和英伟达H100 SXM相比,MI300A的内存容量、峰值内存带宽、FP64精度HPC矩阵及向量峰值性能均更高。
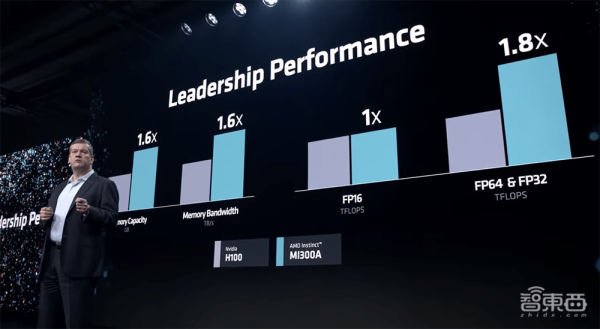
AMD正在设定能效创新的步伐,其30×25目标旨在从2020~2025为AI训练及HPC服务器处理器和加速器提高30倍的能效。
总体来看,APU有四大优势:1)统一内存;2)共享AMD Infinity Cache技术;3)动态功率共享;4)易于编程。这使得APU能为客户提供高性能计算、快速的AI训练和高能效。
通过将统一内存、内存带宽、GPU性能多重优势组合,MI300A在OpenFOAM高性能计算MotorBike测试中,得分是H100的4倍。
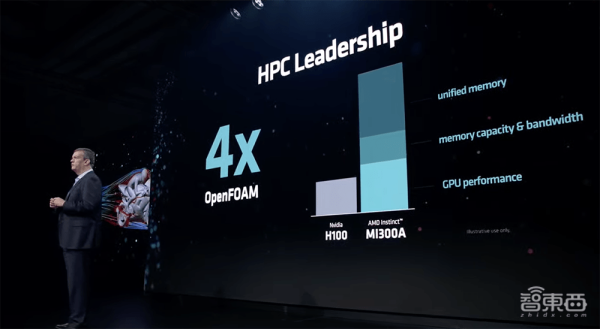
在PeakHPC每瓦性能测试中,MI300A的成绩是英伟达GH200的2倍。

在跑多种高性能计算任务时,相比H100,AMD MI300A均略胜一筹。
美国劳伦斯利弗莫尔国家实验室打造的超级计算机EI Capitan便采用了MI300A,预计将成为世界上第一台2ExaFLOPS超级计算机。
惠普、Eviden、技嘉、超微等是MI300A加速器的OEM和解决方案合作伙伴。
三、ROCm 6软件:针对生成式AI优化,让Llama 2推理延迟暴降
软件是显著提高现有硬件可用性能的关键。
近年来,AMD持续降低用户的迁移成本和开发门槛,来不断补强其从云到端的软件护城河。

其中与AMD Instinct、Radeon GPU搭配使用的ROCm 6开放软件平台对新数据类型、先进图形和核心进行了优化。

ROCm 6增加了对生成式AI的几个新增关键功能的支持,包括Flash Attention、HIP Graph、vLLM等。

与上一代软硬件组合相比,使用MI300X和ROCm 6跑Llama 2 70B文本生成,AI推理延迟速度提高了约8倍。

单张GPU跑Llama 2 13B推理任务时,MI300X的性能是H100的1.2倍。

Meta宣布与AMD扩大合作伙伴关系,将MI300X与ROCm 6结合使用,为AI推理工作负载提供动力,并认可AMD对Llama 2系列语言模型做的ROCm 6优化。
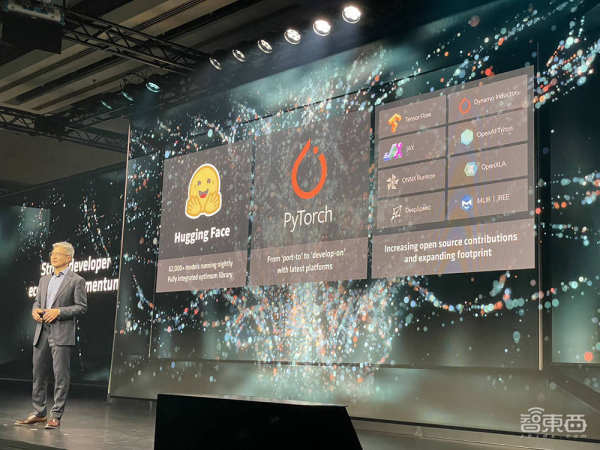
AMD正通过收购AI软件创企Nod.ai和Mipsology,利用广泛的开源AI软件模型、算法、框架、编译器,扩展开源战略,推进基于编译器的优化,加快客户互动等组合策略,来加强软件能力、简化开发,持续改善开发者体验。

AMD还继续通过战略生态系统伙伴关系投资软件能力,数据湖供应商databricks、AI创企Essential AI、为企业客户提供大语言模型的Lamini的联合创始人均来到现场进行分享,谈论他们如何利用MI300X芯片和ROCm 6软件堆栈为企业客户提供差异化的AI解决方案。
从3.0版本开始,OpenAI标准Triton 3.0将添加对AMD GPU芯片开箱即用的支持。

四、Ryzen 8040:为AI PC提供动力,跑生成式AI性能大涨60%
AMD的AI布局已覆盖云边端,除了Instinct加速器外,还有面向数据中心和边缘推理的Alveo加速器、数据中心x86处理器EPYC、用于AI+传感器嵌入式推理的Versal AI Edge、为消费级PC市场打造的Ryzen移动处理器。

面向个人AI处理任务,AMD在NPU中为移动AI处理能效设计了专用AI引擎,在CPU添加了AVX-512 VNNI指令集来加速AI工作负载,Radeon显卡也内置有为并行处理AI工作负载优化的引擎。

AMD Ryzen 8040系列移动处理器为寻求具有可信性能和运行先进AI体验能力的笔记本电脑创意专业人士、游戏玩家和主流用户而设计,采用“Zen 4”CPU和RDNA 3架构GPU。

这款最新处理器支持LPDDR5内存,跑Llama 2大语言模型、视觉模型等生成式AI任务的性能是上一代7040处理器的1.4倍。

与英特尔酷睿i9 13900H相比,Ryzen 8040系列在多线程处理、游戏、内容创作等任务的性能均更加出色。

Ryzen 9 8945HS处理器基于“Zen 4”设计,拥有多达8个核心,可提供16个线程的处理能力。
宏碁、华硕、戴尔、惠普、联想、雷蛇等OEM厂商预计将从2024年第一季度开始供应Ryzen 8040系列。
Ryzen 8040系列移动处理器已经准备好利用Windows 11生态系统的全方位优化性能,包括全面支持Windows 11安全功能。

AMD还广泛提供Ryzen AI软件,供用户在其AI PC上轻松构建和部署机器学习模型。
今天AMD Ryzen AI提供有超过100种AI驱动的体验。1.0版本的Ryzen AI软件支持开源ONNX运行时推理引擎,并在Hugging Face上提供一个预优化的模型市场,使用户几分钟内就能启动和运行AI模型。
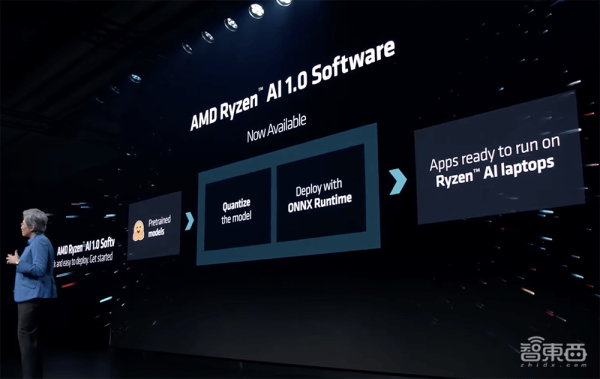
带有Ryzen AI的笔记本电脑可将AI模型卸载到NPU,从而释放CPU以降低功耗,同时延长电池寿命。
Ryzen AI软件现已广泛可用。开发者可以利用它来构建和部署受过PyTorch、TensorFlow等框架训练的AI模型,并在由Ryzen AI提供支持的特定笔记本电脑上运行它们。
开发者可在AMD Ryzen AI计算资源上快速部署生成式AI。该软件获得了对Whisper等自动语音识别模型和OPT、Llama 2等大模型的早期访问支持,以便解锁语音转写、文档摘要等功能。
AMD最近还宣布了Pervasive AI开发者挑战赛,有生成式AI、机器人AI、PC AI三个赛道可选择。其中PC AI是让开发者借助Ryzen AI,使用视觉、语音或领域优化的大语言模型为PC构建应用程序。每个赛道的最高奖金为10000美元,二等奖和三等奖也会获得相应奖励。免费硬件申请将于2024年1月31日截止。
结语:挺进AI芯片市场,AMD蓄势待发
长久以来,英伟达一直是AI芯片游戏规则的制定者。AMD Instinct MI300系列加速器的推出,意味着AMD成为高性能数据中心AI芯片的核心玩家之一,并且是英伟达有力的竞争对手。
AMD初步证明了其在AI硬件研发上的实力,而其劲敌英伟达能横扫AI计算市场的真正王牌是形成强大集群的先进互连技术和持续优化的软件。在今日的发布中,AMD亦展现出其通过软件来升级AI能力的投资布局。
被英伟达主导已久的AI芯片战场,终于出现了令人期待的火药味。在11月举行的第三财季电话会议上,AMD CEO苏姿丰告诉投资者,公司预计明年MI300系列的收入将达到20亿美元。许多业内人士也非常期待看到以一己之力打破英特尔与英伟达垄断的“屠龙勇士”AMD,能够改变AI芯片市场局势,书写新的“AMD yes”故事。
毕竟对于迫切需要更多AI算力的下游客户来说,更多的AI芯片选择,总归不是坏事。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!
