武汉seo今天想聊聊搜索引擎的蜘蛛的工作方式。先说说搜索引擎的原理吧。搜索引擎是把互联网上的网页内容存在自己的服务器上,当用户搜索某个词的时候,搜索引擎就会在自己的服务器上找相关的内容,这样就是说,只有保存在搜索引擎服务器上的网页才会被搜索到。哪些网页才能被保存到搜索引擎的服务器上呢?只有搜索引擎的网页抓取程序抓到的网页才会保存到搜索引擎的服务器上,这个网页抓取程序就是搜索引擎的蜘蛛.整个过程分为爬行和抓取。
一、 蜘蛛
搜索引擎用来爬行和访问网站页面的程序被称为蜘蛛,也可称之为机器人。蜘蛛访问浏览器,就和我们平时上网一个样子,蜘蛛同样会申请访问,得到允许后才可以浏览,可是有一点,搜索引擎为了提高质量和速度,它会放很多蜘蛛一起去爬行和抓取。
蜘蛛访问任何一个网站时,都会先去访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些文件或目录,蜘蛛将遵守协议,不抓取被禁止的网址。
和浏览器一样,搜索引擎蜘蛛也有表明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘蛛。
二、 跟踪链接
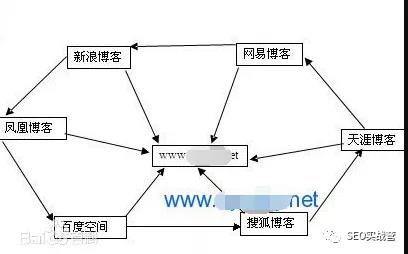
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行一样。
整个互联网是有相互链接的网站及页面组成的。当然,由于网站及页面链接结构异常复杂,蜘蛛需要采取一定的爬行策略才能遍历网上所有页面。
最简单的爬行的策略有:深度优先和广度优先。
1、 深度链接
深度优先指当蜘蛛发现一个链接时,它就会顺着这个链接指出的路一直向前爬行,直到前面再也没其他链接,这时就会返回第一个页面,然后会继续链接再一直往前爬行。
2、 广度链接
从seo角度讲链接广度优先的意思是讲的蜘蛛在一个页面发现多个链接的时候,不是跟着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向第三层页面。
从理论上说,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,都能爬完整个互联网。在实际工作中,没有什么东西是无限的,蜘蛛的带宽资源和蜘蛛的时间也是一样都是有限的,也不可能爬完所有页面。实际上最大的搜索引擎也只是爬行和收录了互联网的一小部分。
3.吸引蜘蛛
蜘蛛式不可能抓取所有的页面的,它只会抓取重要的页面,那么哪些页面被认为比较重要呢?有以下几点:
(1) 网站和页面权重
(2) 页面更新度
(3) 导入链接
(4) 与首页点击距离
4.地址库
搜索引擎会建立一个地址库,这么做可以很好的避免出现过多抓取或者反复抓取的现象,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。
地址库中的URL有以下几个来源:
(1) 人工录入的种子网站。
(2) 蜘蛛抓取页面后,从HTML中解析出新的链接URL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3) 搜索引擎自带的一种表格提供站长,方便站长提交网址
讲到这里,关于搜索引擎已经差不多了,虽然对于真正的搜索引擎技术来说只是一皮毛,不过对于SEO人员已经够用了。原文地址: 这是亿盾武汉seo培训学员博客的第二篇文章,了解了这么多之后是不是更有利于我们对自己网站的优化了捏!
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!