昨天在《js 正则学习小记之匹配字符串字面量》谈到 /"(?:\\.|[^"])*"/ 是个不错的表达式,因为可以满足我们的要求,所以这个表达式可用,但不一定是最好的
昨天在《js 正则学习小记之匹配字符串字面量》谈到 /"(?:\\.|[^"])*"/ 是个不错的表达式,因为可以满足我们的要求,所以这个表达式可用,但不一定是最好的。
从性能上来说,他非常糟糕,为什么这么说呢,因为 传统型NFA引擎 遇到分支是从左往右匹配的,
所以它会用 \\. 去匹配每一个字符,发现不对后才用 [^"] 去匹配。
比如这样一个字符串: "123456\'78\"90"
共 16 个字符,除了第一个 " 直接匹配成功,还剩余 15 个,只有 2 个转义(4 个字符),所以 \\. 会失败 10 次,只有 2 次成功。
这 10 次匹配失败,需要回溯后用 [^"] 才能匹配成功,当然最后一个 " 会直接匹配成功。
很明显,正常的字符串不可能全是转义,正常的字符串才是主流,当然不排除有人故意全转义的情况。
所以这个正则需要10次回溯后才能匹配完成,如果字符串增长到 1K 1M 肿么破呢?
所以我们要修改下这个正则,前后换下位置么?
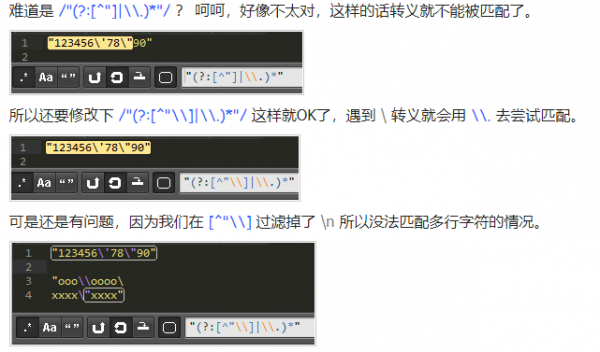
js 中 字符串用 \ 折行是允许的,但是修改后的 正则 没法匹配这样的字符串了,所以我们还得继续修复。
因为 . 没法匹配换行,所以我们要用其他方式表达。
. 是用于匹配除换行符之外的所有字符,难道我们要 [.\n] 来表示么?
这样是不对的,因为 [] 字符集中的 . 不再表示除换行符之外的所有字符,而是字符 . 也就是他本身一个字符而已。
那怎么办呢?
其实换个思路,
\d 表示 0-9
\D 表示 [^0-9]
那么 [\d\D] 就表示所有了,不是么。(新人朋友不知道能不能消化这个知识点。)
同理 [\s\S] [\w\W] 同样可以。
所以 /"(?:[^"\\]|\\[\d\D])*"/ 这样就满足我们的要求了。
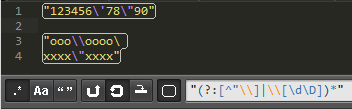
效果不错。
回头过来分分析下他现在的性能吧。
还是这个字符串: "123456\'78\"90" , 正则 /"(?:[^"\\]|\\[\d\D])*"/
共 16 个字符,除了第一个 " 直接匹配成功,还剩余 15 个,有 2 个转义(4 个字符),[^"\\] 能匹配成功 10 个字符,只有 2 次失败。
为什么不是 4 次失败呢,明明有4个字符啊。\\ 虽然是2个字符,但是读到第一个 \ 就匹配失败,然后用 \\[\d\D] 匹配成功,
占用掉了两个字符 \\ 下次用下一个o开始匹配,所以只有2次回溯。
只有 2 次需要回溯,然后用 \\[\d\D] 匹配成功。当然最后一个 " 还是会直接匹配成功。
所以从 10 次回溯,减少到了 2 次,虽然正则比昨天臃肿了很多,但至少性能提升了不止一个等级。
OK,今天的分享完毕,明天见。
来源:脚本之家
链接:https://www.jb51.net/article/184337.htm
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!