
2023年9月 29日,由阿里云、NVIDIA联合主办,阿里云天池平台承办的“NVIDIA TensorRT Hackathon 2023生成式 AI模型优化赛”圆满落幕。该赛事自2020年以来,已成功举办三届,本届赛事于今年 7月启动,吸引了来自全国729支开发者团队报名参赛,其中共有 40支团队晋级复赛,最终 26支团队于决赛中脱颖而出,分获冠军/亚军/季军及优胜奖,展现出了卓越的技术实力。

解锁 TensorRT-LLM挖掘生成式 AI新需求
今年的NVIDIA TensorRT Hackathon着重提升选手开发 TensorRT应用的能力。
在过去的一年里,生成式 AI迎来了爆发式增长。计算机能够批量生成大量图像和文本,有的甚至能够媲美专业创作者的作品。这为未来生成式 AI模型的发展铺平了道路,令人充满期待。正因如此,NVIDIA TensorRT Hackathon 2023选择生成式 AI模型作为比赛的主题,以激发选手的创新潜力。
今年的比赛设置了初赛和复赛两组赛题——初赛阶段,选手需要利用 TensorRT加速带有 ControlNet的 Stable Diffusion pipeline,以优化后的运行时间和出图质量作为主要排名依据;复赛为开放赛题,选手可自由选择公开的 Transformer模型,并利用 TensorRT或 NVIDIA TensorRT-LLM进行模型推理优化。
NVIDIA TensorRT™作为 GPU上的 AI推理加速库,一直以来都备受业界认可与青睐。本次比赛的背后是 NVIDIA TensorRT开发团队对产品不断进行改进和优化的结果。通过让更多模型能够顺利通过 ONNX自动解析得到加速,并对常见模型结构进行深度优化,极大地提高了 TensorRT的可用性和性能。这意味着大部分模型无需经过繁琐的手工优化,就能够在 TensorRT上有出色的性能表现。
TensorRT-LLM是 NVIDIA即将推出用于大语言模型推理的工具,目前已于官网开放试用。作为此次复赛推荐使用的开发工具之一,TensorRT-LLM包含 TensorRT深度学习编译器,并且带有经过优化的 CUDA kernel、前处理和后处理步骤,以及多 GPU/多节点通信,可以在 NVIDIA GPU上提供出类拔萃的性能。它通过一个开源的模块化 Python应用 API提高易用性和可扩展性,使开发人员能够尝试新的 LLM,提供最顶尖的性能和快速自定义功能,且不需要开发人员具备深厚的 C++或 CUDA知识。
作为本次大赛的主办方之一,阿里云天池平台为参赛选手提供了卓越的云上技术支持,在阿里云GPU云服务器中内置 NVIDIA A10 Tensor Core GPU,参赛者通过云上实例进行开发和训练优化模型,体验云开发时代的AI工程化魅力。同时,由NVIDIA 30名工程师组成导师团队,为晋级复赛的 40支队伍提供一对一辅导陪赛,助力选手获得佳绩。
从实践到迭代脑力与创造力的集中比拼
本次比赛中涌现出大量优秀的开发者。在获奖的 26支团队中,有不少团队选择借助 TensorRT-LLM对通义千问-7B进行模型推理优化。
通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的 70亿参数规模的模型,基于 Transformer的大语言模型,在超大规模的预训练数据上进行训练得到。在 Qwen-7B的基础上,还使用对齐机制打造了基于大语言模型的 AI助手 Qwen-7B-Chat。
获得此次比赛一等奖的“无声优化者(着)”团队,选择使用 TensorRT-LLM完成对 Qwen-7B-Chat实现推理加速。在开发过程中,克服了 Hugging Face转 Tensor-LLM、首次运行报显存分配错误、模型 logits无法对齐等挑战与困难,最终在优化效果上,吞吐量最高提升了4.57倍,生成速度最高提升了5.56倍。
而获得此次赛事二等奖的“NaN-emm”团队,在复赛阶段,则选择使用 TensorRT-LLM实现 RPTQ量化。RPTQ是一种新颖的基于重排序的量化方法,同时量化了权重与中间结果(W8A8),加速了计算。从最开始不熟悉任何 LLM模型,到后续逐步学习和了解相关技术,“NaN-emm”团队启用了GEMM plugin,GPT Attention plugin,完成了 VIT、Q-Former、Vicuna-7B模型的转化,最终通过 40个测试数据,基于 Torch框架推理耗时 145秒,而经过 TensorRT-LLM优化的推理引擎耗时为 115秒。
本次大赛还涌现了一批优秀的开发者,本届参赛选手邓顺子不仅率领队伍获得了一等奖,还收获了本次比赛唯一的特别贡献奖。他表示,2022年的 Hackathon比赛是他首次接触 TensorRT,这使他对模型推理加速产生了浓厚的兴趣。尽管当时未能进入复赛,但那次经历让他深感自身技能的不足。在上一次比赛中,他目睹了顶尖选手使用 FasterTransformer在比赛中取得领先地位,这一经历让他对 AI技术有了更深入的理解和追求。随后,他积极做 TensorRT上的模型开发,特别是对 ChatGLM/Bloom等新兴模型进行了优化,感受到了 TensorRT的强大。
今年,他再次参加了 TensorRT Hackathon 2023,利用 TensorRT-LLM成功优化了 QWen大模型,实现了自己的梦想。他感谢主办方给予的机会,团队的支持,以及所有参赛者的努力,他期待未来能与大家一起为 AI技术的发展创造更多奇迹。
人工智能应用场景创新日新月异,AI模型的开发与部署也需要注入新的动能。在此次赛事中,选手们基于 TensorRT挖掘出更多的潜能和功能需求。未来,阿里云和NVIDIA还将持续为开发者和技术爱好者提供展示技能和创意的平台,天池平台将与更多优秀的开发者一同推进 TensorRT的发展,让 AI在 GPU上更容易、更高效地部署。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!
近日,杭州熙凰科技集团有限公司成为阿里云产品生态合作伙伴。未来,熙凰集团将携手云计算与科技智能的力量,共同建设影响世界的数字化企业服务产品和解决方案,为全球企业带来持续成功的客户价值。
阿里云成为国内首个加入大模型开源行列的大型科技企业。就在昨天,阿里云公开表态,把自家的通义千问大模型开源。阿里云把通用70亿参数模型,包括Qwen-7B和对话模型Qwen-7B-Chat这两款大模型产品给开源了。

6月1日,2023阿里云峰会·粤港澳大湾区在广州举行,会上阿里云正式推出《云卓越架构白皮书》,为企业用云管云解决方案和产品化落地提供指引,助力企业构建更加安全、高效、稳定的云架构。本书由阿里云架构师团队、产品团队、全球交付团队等众多团队基于过去多年服务企业的经验总结共同撰写,从安全合规、稳定性、成本

5月17日,2023阿里云峰会·常州站上,阿里云正式发布第八代企业级计算实例g8a以及性能增强性实例g8ae。两款实例搭载第四代AMDEPYC处理器,标配阿里云eRDMA大规模加速能力,网络延时低至8微秒。其中,g8a综合性价比平均提升15%以上,g8ae算力最高提升55%,在AI推理与训练、深度学
文|智能相对论作者|叶远风产业升级如火如荼,通过数字化、智能化来激发“新动能”,已经成为普遍共识。但是,作为一个泛概念,“新动能”到底是什么,又如何具体到一些举措、动作上,才能确保落地,从而切实推动产业升级?业界需要一个关于“新动能”如何被激发的切实路线图。事实上,针对产业升级的“新动能”,最终还是
自字节跳动发布豆包大模型,互联网大厂纷纷就位,击穿“地板价”的打法从C端向B端拓展。这也成为今年“618”最亮眼的价格战。5月15日,字节跳动率先宣布豆包大模型已通过火山引擎开放给企业客户,大模型定价降至0.0008元/千Tokens;5月21日,阿里云宣布0.0005元可得1000tokens,百

2023年可以说是人工智能行业最振奋的一年,大模型的能力每隔一段时间就会上一个新台阶,汹涌澎湃的技术革命迅速影响着每一个人的生活,AGI不再是一种技术理想,而是触手可及的现实。到了2024年,人工智能的热度不减,但口口相传的“百模大战”并未上演。资本市场罕见地“降温”,不少大模型悄无声息地消失,有机

ChatGPT运行日耗70万美金!GPT-4训练成本破10亿美金大关!OpenAI2024年财务警钟敲响,破产风险浮现!国产大模型烧钱大战升级!百度、科大讯飞、阿里、腾讯等巨头已烧掉上百亿资金!大模型背后的“烧钱”豪赌,谁能笑到最后?降低成本大模型成本怎么降低?有两条比较实用的路径大模型背后的成本确
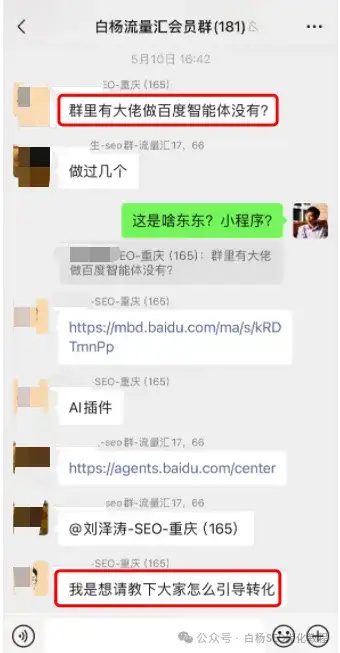
前言:这是白杨SEO公号原创第530篇。为什么写这个?一个星期多前在白杨流量汇群看到有人问,自己实战测试研究了下分享给大家,也许对大家有点用。本文大纲:1、百度智能体是什么?2、百度智能体有什么用?3、百度智能体怎么创建?4、百度智能体如何用(营销)?百度智能体是什么?百度智能体,准确的叫法应该是百

C114讯5月21日消息(九九)阿里云今天抛出重磅炸弹:通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。这意味着,1块钱可以买200万tokens,相当于5本《新华字典》的文字量。这款模型最高支持1千万toke
近日,OpenAI宣布推出其最新旗舰生成式AI模型GPT-4o。相较于GPT-4Trubo,GPT-4o速度更快、价格也更便宜据悉,ChatGPT可以读取人类的情绪,但读取过程有一点困难。OpenAI,是一家位于美国旧金山的人工智能研究公司,现由营利性公司OpenAILP及非营利性母公司OpenAI

随着人工智能技术的飞速发展,大语言模型(LargeLanguageModels,LLMs)在各行各业的应用日益广泛,尤其是在软件开发、数据分析、客户服务等领域。蘑菇云创客空间[445期开放夜]就以“ChatGPT、Gemini、通义千问等一众大语言模型,哪家更适合您”这样的主题,开展了一次深度的大语













