

2023年可以说是人工智能行业最振奋的一年,大模型的能力每隔一段时间就会上一个新台阶,汹涌澎湃的技术革命迅速影响着每一个人的生活,AGI不再是一种技术理想,而是触手可及的现实。
到了2024年,人工智能的热度不减,但口口相传的“百模大战”并未上演。资本市场罕见地“降温”,不少大模型悄无声息地消失,有机会进入决赛圈的大模型创业者,仅剩下寥寥数家。
其中就有孵化出海螺AI的MiniMax,一家不为太多人所熟知,估值却早已超过25亿美元的现象级独角兽。
01 技术路线几乎没有退路
目前国内估值超过10亿美元的大模型创业团队只有五六家,MiniMax恰恰又是其中最为特殊的存在:
1、月之暗面、百川智能、零一万物等均成立于2023年,MiniMax却是一家诞生于2021年的企业,比友商们早了两年时间。
2、有别于李开复、王小川等人的“明星”身份和高调风格,MiniMax的创始人闫俊杰不可谓不低调,很少在公开场合露面。
3、“抢算力”俨然是整个AI行业的常态,MiniMax没有够购买任何GPU,而是以相对便宜的价格找火山引擎租了大量GPU算力。
为何特立独行的MiniMax能够活下来?答案就藏在闫俊杰时常提及的一句话里:“我选的技术路线几乎没有退路”。

直接的例子就是MoE(混合专家模型)上的“豪赌”。
时间回到2023年夏天,国内的大模型厂商们纷纷加快了研发进度,摆在MiniMax面前的现实问题是:自家2B和2C的产品已经有很多用户,传统dense(稠密)模型生成token的成本太高,延时太严重;在计算资源有限的情况下,只有MoE才能训练完当时的数据。
理论上讲,MoE相较于dense模型的预训练速度更快,在相同参数的情况下,有着更快的推理速度,但在微调方面存在诸多挑战,比如泛化能力不足容易引发过拟合现象,属于典型的“技术派才有的红利”。
其他厂商选择dense模型快速迭代的时候,MiniMax放了80%以上的算力和研发资源做MoE,而且没有Plan B。
拐点出现在2024年初,MiniMax发布了国内首个基于MoE架构的abab 6,找到了越来越多加速实现Scaling Laws的途径,包括改进模型架构、重构数据pipeline等等,并在三个月后研发出了更强大的abab 6.5。
正如外界所熟知的,长文本能力在2024年成为生产力工具的“胜负手”,万亿参数的abab 6.5已经200k tokens 的上下文长度,综合能力已经不逊于国外主流大模型;使用同样的训练技术和数据的abab 6.5s,进一步提升了推理速度,可以在1秒内处理近3万字的文本。
按照业界常用的“大海捞针”机制,即在很长的文本中放入一个和该文本无关的句子(针),然后通过自然语言提问模型,看模型是否准确将这个针回答出来。在891次问答中,abab 6.5均能正确回答。
现在,MoE模型已经上升为行业共识,被认为是高性能AI大模型的必选项,而MiniMax已经在这条路上“抢跑”了一年。
02 技术驱动的产品方法论
让许多人没想到的是,一群痴迷于技术的工程师,“意外”做出了多个日活用户超过100万的产品,包括Glow、星野、海螺AI等,涵盖内容社区、生产力工具等不同方向。
曾有媒体在采访时询问闫俊杰:“你们第一个模型还没做出来,就招了产品经理,当时你如何向他描述你想要一个怎样的产品?”出乎预料的是,闫俊杰给出的回答只要三个字:“不知道。”
闫俊杰口中的“不知道”,源于对技术的敬畏:当前AI原生的超级产品,无不源自突破性的技术进步。
比如搜索问答几乎是所有对话式AI的标配,也是我们使用生产力工具提升工作效率的刚需功能。但越是基础的功能,越能验证生产力工具的价值,考验背后大模型的能力。
百度发布2024年Q1财报后,我们同时在海螺AI和国外的一款产品进行了对比,用户体验可谓高下立见:

海螺AI整理出了百度的核心业务信息,包括营收、利润等关键数据,以及百度智能云、开发者社区、百度APP、萝卜快快等核心业务数据,有着清晰的逻辑和侧重,并且每条内容都关联了对应的信息源,甚至在末尾附加了和百度财报相关的常见问题。
另一款产品也准确回答了财报的核心信息,但仅仅引述了一些媒体报道,输出内容的结构化很弱,需要人工二次处理信息。和直接用搜索引擎查找信息的方式相比,并未节省太多的时间。
再比如长尾内容的检索和生成能力。像百度财报这样的热门议题,很容易找到相关的媒体报道,一些小众的长尾内容,似乎更能考验生产力工具的内容检索和生成能力。
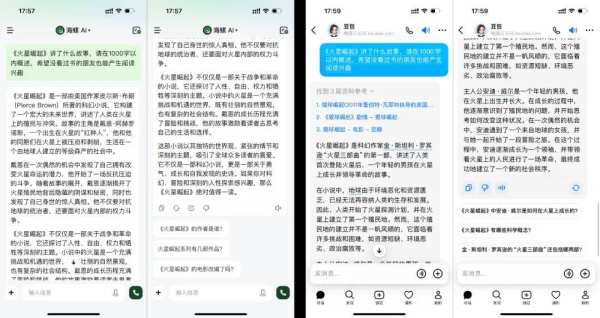
我们的问题是皮尔斯·布朗的代表作《火星崛起》,曾被《娱乐周刊》评为2014年度最佳图书,但知名度不如《火星救援》、《星球崛起》等可能被AI混淆的名著。海螺AI准确理解了我们的需求,生成的故事梗概可圈可点,并给出了深刻的评价;豆包将我们的需求误解为《星球崛起》,生成的内容居然是《火星三部曲》的介绍。
技术的上限左右着产品的上限。
MiniMax之所以做出了海螺AI这样“能打”的生产力工具,根源在于技术驱动的产品方法论,只有具备足够好的产品能力,才能承接和转化取得的技术进展,否则会落得一场空。
当然,MiniMax也有自己的“野心”。就像闫俊杰所筹划的:“在技术快速进化的窗口关闭前,做出用户量巨大的To C产品。”
03 做普通人每天用的产品
资本圈里流传着一句话:判断一位人工智能创业者是否真正的AGI信仰,就看这个人创业是在2023年之前还是之后。作为普通用户,则有另一套判断标准,即能不能解决实际问题,扎扎实实地提高工作效率。
行事低调的闫俊杰,很少围绕AGI的话题高谈阔论,但在媒体采访时讲述了自己朴素的信仰:Intelligence with everyone。
怎么理解“与用户共创智能”?海螺AI无疑是最直观的研究对象。
生产力工具作为当下最拥挤的大模型赛道,市面上的产品已经多达几十款,豆包、文心一言、智谱清言、Kimi……哪怕是在高度内卷的局面下,肩负MiniMax信仰的海螺AI,依然表现出了差异化和稀缺性。
首先是简洁的产品设计。
为了争夺用户的注意力和时长,越来越多的对话式AI产品在首页上添加了丰富的菜单栏,努力向用户表达功能的多样性。海螺AI不可谓不克制,首页上除了简单的功能引导和对话框外,并没有其他影响注意力的元素。
不同的设计风格,似乎谈不上孰优孰劣,但从生产力工具的定位来说,页面的简洁与否和大模型能力不无关系。倘若大模型的能力足够强大,哪怕没有花里胡哨的功能露出,也可以通过生成的内容占领用户心智。刻意强调功能的多样性和玩法的趣味性,反而在大模型的能力上漏了怯。
其次是过硬的产品能力。
诸如搜索问答、语音对话、长文总结等功能,早已是对话式AI产品的标配,也是高度同质化的主要诱因。但只要深入使用一段时间,或者进行简单的结果对比,并不难判断能力上的高下,找到最适合的生产力工具。
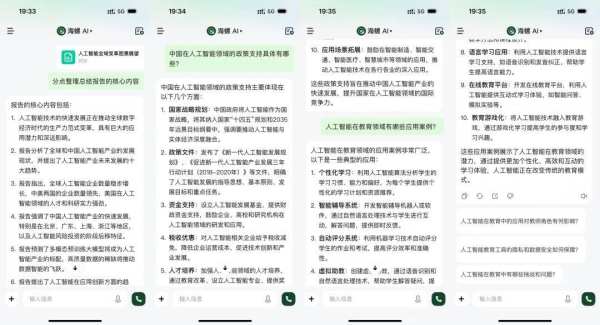
而产品能力的强弱,往往体现在一些细节中。以我们高频使用的长文总结为例,将第三方行业报告上传到海螺AI,可以准确梳理报告的核心信息,并根据报告内容进行对话。原先阅读一篇报告需要至少两个小时的时间,现在不到5分钟就能完成,工作效率可以说是实现了指数级增长。
然后是多元的使用场景。
有些产品尽可能在首页上推荐足够多的“角色”,来告诉我们有很多使用场景,适合不同的用户。仅仅在prompt下功夫,当真可以满足不同人群的需求吗?市场初期也许奏效,可终归不是解决问题的最优解。
海螺AI的答案是从能力上满足不同人群的需求:帮研究人员快速总结和分析长篇学术论文或研究报告、帮内容创作者整合关键信息并生成爆款文章、帮知识工作者整理和回顾学习资料、为日常用户提供生活中的即时帮助……就像是一个能打的六边形战士,背后是万亿参数MOE大模型的底气。
一言以蔽之,只有做出足够产品化、能服务大众的AI技术和产品,才可以给社会带来足够高的反馈。在MiniMax的认知里,AGI不是原子弹那样的大杀器,而是普通人每天会用的产品和服务。
04 写在最后
每一次代际演变的出现,都会经历百花齐放到超级APP“统治”市场的过程。
大模型的产品化也不例外。现阶段AI产品的核心价值,主要来自模型性能和算法能力,不排除会上演“赢者通吃”的一幕。特别是对于寻求生产力的用户,拥抱海螺AI这样的超级APP,卸载掉“尝鲜”时下载的几十个APP,将是可以预见的结果。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!
ChatGPT运行日耗70万美金!GPT-4训练成本破10亿美金大关!OpenAI2024年财务警钟敲响,破产风险浮现!国产大模型烧钱大战升级!百度、科大讯飞、阿里、腾讯等巨头已烧掉上百亿资金!大模型背后的“烧钱”豪赌,谁能笑到最后?降低成本大模型成本怎么降低?有两条比较实用的路径大模型背后的成本确
前言:这是白杨SEO公号原创第530篇。为什么写这个?一个星期多前在白杨流量汇群看到有人问,自己实战测试研究了下分享给大家,也许对大家有点用。本文大纲:1、百度智能体是什么?2、百度智能体有什么用?3、百度智能体怎么创建?4、百度智能体如何用(营销)?百度智能体是什么?百度智能体,准确的叫法应该是百

C114讯5月21日消息(九九)阿里云今天抛出重磅炸弹:通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。这意味着,1块钱可以买200万tokens,相当于5本《新华字典》的文字量。这款模型最高支持1千万toke
近日,OpenAI宣布推出其最新旗舰生成式AI模型GPT-4o。相较于GPT-4Trubo,GPT-4o速度更快、价格也更便宜据悉,ChatGPT可以读取人类的情绪,但读取过程有一点困难。OpenAI,是一家位于美国旧金山的人工智能研究公司,现由营利性公司OpenAILP及非营利性母公司OpenAI

随着人工智能技术的飞速发展,大语言模型(LargeLanguageModels,LLMs)在各行各业的应用日益广泛,尤其是在软件开发、数据分析、客户服务等领域。蘑菇云创客空间[445期开放夜]就以“ChatGPT、Gemini、通义千问等一众大语言模型,哪家更适合您”这样的主题,开展了一次深度的大语

赶超GPT-4的阶段性升级,可以看作是国产大模型有序迭代部署、不断拉近差距的标志,切莫像手机跑分那样,在过度营销的作用下,沦为被群嘲的对象。

5月9日,记者获悉,微博已接入阿里云通义大模型,提升内容生产效率和社区活跃度。微博不仅是阿里云最早一批上云客户,也是阿里云通义大模型的最早客户。微博COO、新浪移动CEO王巍表示,AIGC发展速度远超想象,包括通义2.5在内,已涌现出不少大模型能力超越GPT4。同时他指出,大模型开源势不可挡。“阿里

5月9日阿里云AI峰会,通义灵码宣布推出企业版,满足企业用户的定制化需求,帮助企业提升研发效率。通义灵码是国内用户规模第一的智能编码助手,基于SOTA水准的通义千问代码模型CodeQwen1.5研发,插件下载量已超350万。通义灵码熟练掌握Java、Python、Go、JavaScript、Type

5月9日消息,通义大模型品牌升级,“通义千问APP”更名为“通义APP”,集成通义大模型全栈能力,免费为所有用户提供服务。通义APP以性能媲美GPT-4Turbo的基模为底座,并把通义实验室前沿的文生图、智能编码、文档解析、音视频理解、视觉生成等能力“Allinone”,成为每个人的全能AI助手。通













