




随着大模型技术迎来颠覆性突破,新兴AI应用大量涌现,不断重塑着人类、机器与智能的关系。
为此,昆仑万维集团重磅推出《天工一刻》系列产业观察栏目。在本栏目中,我们将对大模型产业热点、技术创新、应用案例进行深度解读,同时邀请学术专家、行业领袖分享优秀的大模型行业趋势、技术进展,以飨读者。
小模型与端侧模型,2024大模型赛道最重要的两个议题。
就在6月28日,谷歌刚刚发布了Gemma系列的最新SOTA(State-of-the-Art,当前最领先)模型Gemma-2,有9B和27B两种大小,谷歌还称计划在未来几个月发布2B版本,更适合手机终端运行。
而不久前的苹果WWDC大会上,苹果先是推出了端侧AI系统Apple Intelligence,随后又在技术博客中介绍了其自研的端侧3B小模型——性能全面超越主流7B大模型。
在更早之前的4月,则更是全球小模型和端侧模型“神仙打架”的月份。短短的一月之内,Meta、微软、苹果等集中发布Llama-3、Phi-3、OpenELM,对小模型和端侧模型产业带来极大冲击。如果把时间放宽到2024年上半年,则还有MobileLLM、Gemma-7B、Qwen-7B、MiniCPM、TinyLlama等一系列代表玩家。
手机厂商更是早早就杀入局中。在全球手机/PC市场保有量居高不下、用户换机周期高达51个月的当前,AI大模型无疑成为各大终端厂商全力押注之处。
从2023年下半年开始,华为、小米、OPPO、vivo、苹果、三星,以及产业链上的高通、联发科等都陆续推出手机AI大模型或手机AI大模型芯片。根据Counterpoint数据,仅在2024年第一季度,全球具有生成式AI功能的智能手机型号就从16个增加到30多个,AI手机销量占比从1.3%提高到6%。
大模型厂商、终端厂商、终端芯片厂商……小模型与端侧模型的兴起,已经逐渐成为产业共识。
一、端侧模型 vs 小模型
严格来说,“端侧模型”与“小模型”的概念并不能直接等同。
“小模型”通常指的是那些参数规模远少于GPT-3或Llama-13B的大语言模型,几个具有代表性的参数为1.5B、3B、7B等。
这些小模型虽然参数规模较少,但通过特定的设计和优化,仍然能够在某些任务上达到与大型模型相似的性能,从而降低计算资源消耗,提高能耗比。
“端侧模型”则通常指的是部署在手机、电脑、或其他移动设备、嵌入式系统等资源受限的设备上的模型,这些设备的计算资源(AI算力、内存等)往往不足以直接运行大型的预训练模型,同时对于端侧的能耗、发热等问题有着更为极致的要求。
因此,端侧模型需要特别设计以减少模型大小和模型架构,以便能够在端侧设备上高效运行。
其中,学术界关于小模型的技术研究较为深入,而产业界更注重端侧模型的工程化研究。
不过目前手机、PC等终端设备受限于计算资源问题,大多只能流畅运行小模型,因此大量相关研究都存在重合领域。本文内容对于两类模型均有所覆盖。
二、小模型三大技术流派
目前来看,全球关注度最高的小模型和端侧模型,仍要数Meta、微软、苹果分别与今年发布的Llama-3、Phi-3-mini、OpenELM/Apple Foundation Model。
从最底层技术架构上来说,Llama-3、Phi-3、OpenELM/Apple Foundation Model都采用了当前主流的、由GPT引领的Decoder-only Transformer架构。
同时,当前主流小模型也统一采用了“预训练Pre-train + 微调Fine-tune + 对齐Alignment”的模型训练思路。
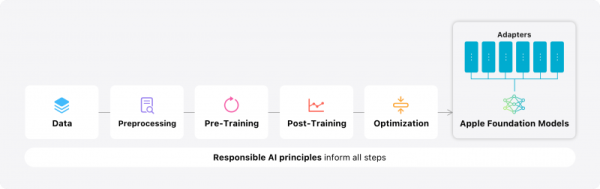
(苹果模型训练思路,技术博客《Introducing Apple’s On-Device and Server Foundation Models》)
从整体来说,当前主流小模型的核心技术思路与“大”模型一致。
不过具体到各个小模型的模型设计、训练方法、数据工程领域,则衍生出不同的技术派别。
1、暴力美学派
在众多派别中,最具代表性玩家之一当属Llama-3。
Meta的Llama是大模型领域市场认知度最高的开源大模型系列。2024年4月,Meta在官网通过技术博客的形式正式发布了最新的Llama-3系列大模型,在当时的主流榜单上取得了不俗的成绩。
其中,Llama-3共有80亿(8B)、700亿(70B)两种参数;而根据Meta透露,其4000亿(400B)参数的Llama-3模型还在训练当中。
Llama-3在模型架构上跟上一代Llama-2差别不大,但训练数据规模上却有了惊人的提升。
根据Meta技术博客内容,Llama-3的训练数据量达到了惊人的15万亿(15T)tokens!是Llama-2的7倍。

(Meta Llama-3训练数据,技术博客《Introducing Meta Llama 3: The most capable openly available LLM to date》)
要知道,根据Chinchilla Scaling Laws定律,对于一个8B的大模型,最优训练数据规模仅为0.2万亿tokens。
相比起来,Llama-3砸进去的15万亿tokens堪称数据“暴力美学”——但也确实卓有成效,Llama-3-8B在同等规模的模型间取得了惊人的优秀表现。
Meta研究人员还表示,15万亿并非是终点。研究人员在对Llama-3训练超过15万亿规模的数据之后,模型依旧展现出了对数线性级(log-linearly)的性能提升。
2、精耕细作派
虽然几乎同期发布,但微软Phi-3的训练数据思路与Llama-3大不相同。
Phi是微软旗下专注于开源小模型的系列模型。其中,Phi-1与Phi-2系列的模型参数规模都不超过3B,但表现十分亮眼。
Phi-3系列由微软于2024年4月发布,不仅依旧将研究重心放在小模型上,Phi-3的技术论文标题更是直白地写为《Phi-3技术报告:一个能在手机本地运行的高性能语言模型》,重点瞄准了端侧AI。
Phi-3系列包含3个版本:Phi-mini-3.8B、Phi-small-7B、Phi-medium-14B。
在训练数据设计思路上,Phi-3与Llama-3有着最大的分歧。根据技术论文信息,Phi-3的训练数据仅为3.3万亿tokens,只有Llama-3的四分之一不到。
但是,Phi-3研究人员对这3.3万亿的数据进行了大量数据工程研究,保证高质量数据的筛选与把控。

(微软Phi-3训练方案,技术论文《Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone》)
这一思路沿用自微软Phi系列开山论文《Textbooks Are All You Need》的高质量数据集路线。在该论文中,微软用规模仅为 7B token 的“教科书级高质量数据”训练出1.3B参数的Phi-1,并自此沿用了这一路线。
Phi系列在训练数据领域的“精耕细作”与Llama系列的“暴力出奇迹”形成了强烈反差,也是当前两派技术争论的焦点之一。
3、架构创新派
除了上述Phi-3与Llama-3这类在数据工程、数据训练等领域展开的研究外,目前业内也有不少玩家重点关注小模型与端侧模型的架构创新,试图打造更为“原生”的小模型与端侧模型。
受限于端侧软硬件与小模型规模的天然限制,这类创新架构主要关注如何在保持注意力机制有效性的前提下,减少计算量和内存占用,提高模型的训练和推理效率。
例如,苹果于4月推出的OpenELM系列模型采用了细粒度的优化技术,用以提升模型的性能和资源利用效率。举例而言,在模型架构设计方面,OpenELM采用模型分层精调设计,使得整个模型可以面向硬件瓶颈做精细设计和优化,提高了小模型在端侧的运行效率。
Meta的MobileLLM系列则更是开始研究1B以下小模型的实验和验证,在其2024年2月的论文中分别提出了125M和300M两种最新小尺寸的模型,通过模型架构创新与模型参数高效分配,在该参数范围内取得了最好效果(SOTA),其API调用任务精度甚至做到了与Llama-2-7B接近,进一步降低了小模型端侧运行的潜在设备门槛。
三、热点技术
作为当前最火的技术领域,小模型/端侧模型的各个领域都衍生出不少热点技术方向,如模型架构创新领域的分组查询注意力(Grouped-query Attention)、稀疏注意力(Sparse Attention)、混合注意力(Mixed Attention)、线性复杂度注意力(Linear Complexity Attention)、模块化网络(Modular Network)等。
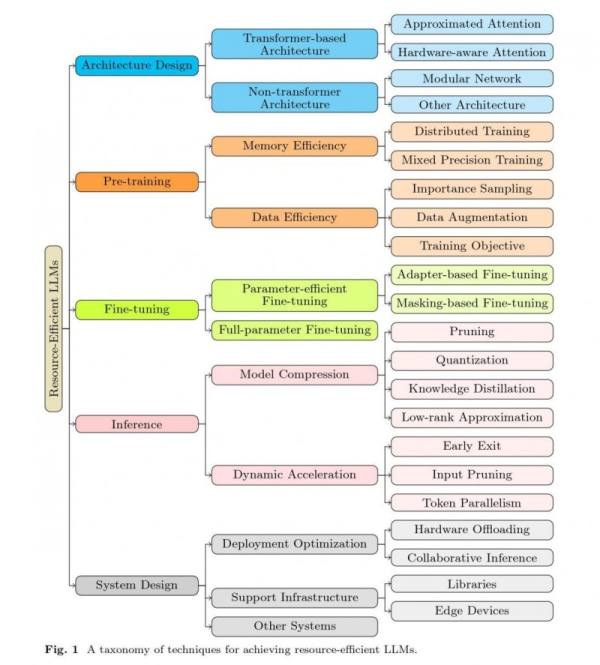
(在大模型训练及推理不同环节提高模型效率的相关研究,论文《Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models》)
在小模型与端侧模型的设计中,“高效(Efficient)”是一个核心思路,这一点在各类注意力(Attention)网络的架构创新中体现得尤为明显。
注意力网络是Transformer大模型技术的核心。传统的全局注意力网络需要对每个输入序列的所有位置进行计算,导致算力和内存需求暴增——这一点在端侧十分不利。
为了提高模型效率,无数研究人员自大模型诞生以来就投入有关注意力网络的创新中。
一个具有代表性的技术路径是稀疏注意力(Sparse Attention)。
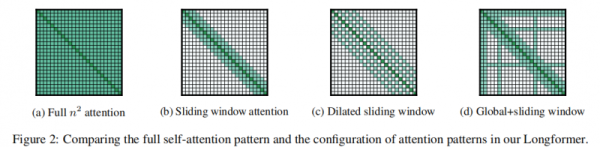
(图(a)为全局注意力,图中(b) (c) (d)为Longformer作者提出的三种不同稀疏注意力机制,能够显著降低计算量,论文《Longformer: The Long-Document Transformer》)
谷歌在6月28日发布的最新SOTA模型Gemma-2中就用到了稀疏注意力网络。Gemma-2拥有9B和27B两种大小,谷歌称更适合手机终端运行的2B版本也即将发布。
在Gemma-2技术论文中谷歌表示,Gemma-2引入了交织局部-全局注意力(Interleaving Local-Global Attentions),其在每隔一层之间交替使用局部滑动窗口注意力(Local Sliding Window Attention)和全局注意力。最终Gemma-2在同等规模模型上达到了最新SOTA,甚至某些性能能够与其2-3倍大的模型相媲美。
此外,分组查询注意力机制(Grouped-query Attention, GQA)也是当前在小模型领域应用最广泛的技术之一。
GQA技术于2023年底由Google Research团队提出,是一种在大模型多头注意力机制(Multi-head Attention, MHA)和多查询注意力机制(Multi-query Attention, MQA)之间进行插值的方法。
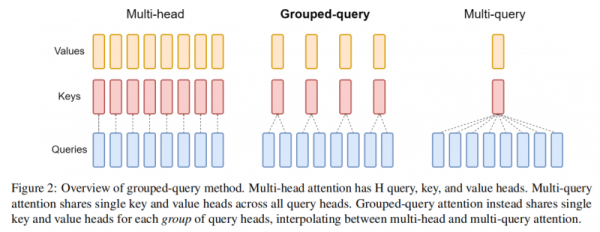
(GQA技术思路,论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》)
虽然GQA技术正式提出还不到1年时间,但在Phi-3、Llama-3、苹果端侧模型、MobileLLM、Gemma-2、以及几乎所有主流小模型中全部采用了这一技术,其火爆程度可见一斑。
相较而言,多头注意力机制(Multi-head Attention, MHA)的模型表现质量更好,但多查询注意力机制(Multi-query Attention, MQA)的模型响应速度更快。
GQA则通过使用多个Key-value Head(数量少于Query Head)的方法进行“折中”,使得最终模型表现质量能够与MHA媲美的同时,模型响应速度提高3倍,达到MQA的标准,从而取得模型性能/表现的更好平衡。
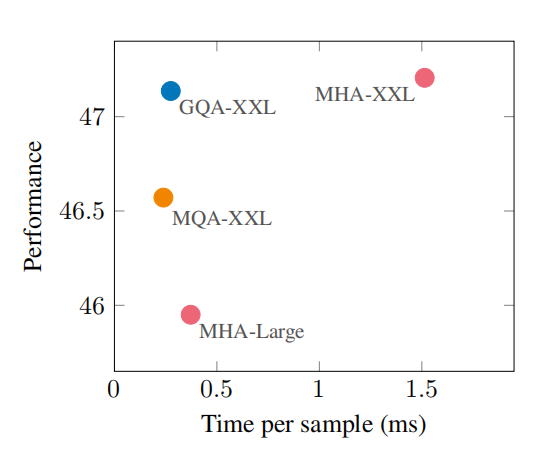
(不同路径下模型质量与响应速度,论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》)
在数据资源日益稀缺的当下,合成数据(Synthetic Data)也是大模型业内最关注的技术突破之一。
Meta、微软、苹果等主流小模型都在其技术报告中提及了合成数据的使用,其中:Meta表示使用Llama-2生成训练数据用于支持Llama-3的文本质量分类器(text-quality classifiers);微软表示Phi-3使用合成数据来训练模型的推理能力和部分细分领域能力;苹果则表示在Post-training阶段引入了合成数据。
不过,几家都没有具体透露更为详细的数据组成或内容。
整体而言,小模型和端侧模型目前还在产业发展早期,这几个热点方向仍有待学术与产业界的进一步探索。
四、端侧AI是大模型的“终局”
虽然上文在讨论过程中同时提及了端侧模型与小模型,但具体到端侧,还有很多特有的挑战有待解决。
端侧AI算力不足是个老生常谈的问题,众多端侧AI硬件公司所瞄准的也是这一方向。但事实上,目前端侧模型落地部署的最大瓶颈未必是AI算力——反而是内存。
相比云服务器,手机等端侧设备内存容量和存储空间通常都要小得多。可大模型即使经过压缩,依然会需要占用大量内存和存储空间,这对于资源有限的端侧设备来说几乎难以承受。
同时,端侧设备对功耗和实时性有严格的要求。大模型计算过程中所产生的高功耗会导致设备功耗飙升,甚至导致高温发热、甚至影响系统整体稳定性。
最后,端侧应用还往往需要满足实时性的要求,例如语音识别、图像处理等应用,需要在极短的时间内给出响应。如果只是把大模型进行压缩裁剪,但模型的推理速度不能满足端侧应用的实时性要求,依然不适用于端侧。
设计更小的模型只是第一步,想要模型在端侧落地,必须对模型进行进一步的优化和调整,以确保在有限的内存、算力、功耗、实时性、稳定性 限制下高效运行。
因此,虽然可以通过量化、裁剪等方式将云端大模型压缩成小模型,但具体在端侧模型领域,许多研究人员更倾向于从0构建一个专用小模型或专用端侧模型,而非对现有大模型进行裁剪 。
同时,从发展的眼光看,随着技术的进步和硬件性能的提升,端侧设备能够运行的模型势必会变得更大、功能更全面 。
过去10年间,端侧算力经历了爆发式增长。移动设备、物联网设备、边缘计算设备等的硬件性能显著提升,计算能力不断增强。
举个例子,10年前,苹果iPhone 5s搭载的A7处理器上集成了10亿个晶体管。而10年后的今天,最新一代iPhone 15 Pro Max中的A17 Pro处理器集成了多达190亿个晶体管,算力提升惊人。
20年前,大部分手机甚至还未迈入智能机时代,只能打电话、发送短信、玩贪吃蛇。手机几乎不具备任何多媒体处理能力,摄像头的像素数极低,连视频都无法录制。
而在20年后,手机几乎无所不能,成为人们生活中不可或缺的一部分。
“端侧AI是大模型的‘终局’。”昆仑万维董事长兼CEO方汉这样评价。
方汉认为,在经历完3-5年的换机周期后,主流人群将普遍换上能支撑大模型端侧运行的新手机,这个过程中,更高效、便宜的端侧推理是关键。而大模型战争的“终局”是终端AI手机的全面普及——未来,推理成本将成为用户购机成本的一部分,实现AI的广泛落地。
一直以来,昆仑万维以“实现通用人工智能,让每个人更好地塑造和表达自我”为使命,致力于成为领先的人工智能科技企业,全力推动人工智技术应用落地。
2024年5月,昆仑万维天工AI每日活跃用户(DAU)已超过100万,位列国内人工智能企业第一梯队。未来,昆仑万维也将不断投入前沿技术研发,优化端侧AI系统,让越来越多用户能够享受AI大模型带来的生活便利。
参考资料:
1、Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
2、Gemma 2: Improving Open Language Models at a Practical Size
3、GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
4、How Good Are the Latest Open LLMs? And Is DPO Better Than PPO?
5、Introducing Apple’s On-Device and Server Foundation Models
6、Introducing Meta Llama 3: The most capable openly available LLM to date
7、Longformer: The Long-Document Transformer
8、Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!


